
We import Biden’s approval dataset from fivethirtyeight.com all polls that track the president’s approval, and use lubridate to fix dates.
# Import approval polls data directly off fivethirtyeight website
approval_polllist <- read_csv("https://projects.fivethirtyeight.com/biden-approval-data/approval_polllist.csv")
glimpse(approval_polllist)## Rows: 1,922
## Columns: 22
## $ president <chr> "Joseph R. Biden Jr.", "Joseph R. Biden Jr.", "Jos~
## $ subgroup <chr> "All polls", "All polls", "All polls", "All polls"~
## $ modeldate <chr> "10/18/2021", "10/18/2021", "10/18/2021", "10/18/2~
## $ startdate <chr> "1/19/2021", "1/19/2021", "1/20/2021", "1/20/2021"~
## $ enddate <chr> "1/21/2021", "1/21/2021", "1/21/2021", "1/21/2021"~
## $ pollster <chr> "Morning Consult", "Rasmussen Reports/Pulse Opinio~
## $ grade <chr> "B", "B", "B-", "B+", "B", "B", "B-", "B", "B", "B~
## $ samplesize <dbl> 15000, 1500, 1115, 1516, 1993, 15000, 1200, 15000,~
## $ population <chr> "a", "lv", "a", "a", "rv", "a", "rv", "a", "lv", "~
## $ weight <dbl> 0.2594, 0.3382, 1.1014, 1.2454, 0.0930, 0.2333, 0.~
## $ influence <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,~
## $ approve <dbl> 50, 48, 55, 45, 56, 51, 58, 52, 48, 63, 55, 53, 48~
## $ disapprove <dbl> 28, 45, 32, 28, 31, 28, 32, 29, 47, 37, 33, 29, 47~
## $ adjusted_approve <dbl> 48.6, 50.5, 53.9, 46.5, 54.6, 49.6, 57.0, 50.6, 50~
## $ adjusted_disapprove <dbl> 31.2, 38.8, 33.0, 28.4, 34.2, 31.2, 33.1, 32.2, 40~
## $ multiversions <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA~
## $ tracking <lgl> TRUE, TRUE, NA, NA, NA, TRUE, NA, TRUE, TRUE, NA, ~
## $ url <chr> "https://morningconsult.com/form/global-leader-app~
## $ poll_id <dbl> 74272, 74247, 74248, 74327, 74246, 74273, 74270, 7~
## $ question_id <dbl> 139491, 139395, 139404, 139570, 139394, 139492, 13~
## $ createddate <chr> "1/28/2021", "1/22/2021", "1/22/2021", "2/2/2021",~
## $ timestamp <chr> "09:38:10 18 Oct 2021", "09:38:10 18 Oct 2021", "0~skim(approval_polllist)| Name | approval_polllist |
| Number of rows | 1922 |
| Number of columns | 22 |
| _______________________ | |
| Column type frequency: | |
| character | 12 |
| logical | 1 |
| numeric | 9 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| president | 0 | 1.00 | 19 | 19 | 0 | 1 | 0 |
| subgroup | 0 | 1.00 | 6 | 9 | 0 | 3 | 0 |
| modeldate | 0 | 1.00 | 10 | 10 | 0 | 1 | 0 |
| startdate | 0 | 1.00 | 8 | 10 | 0 | 268 | 0 |
| enddate | 0 | 1.00 | 8 | 10 | 0 | 268 | 0 |
| pollster | 0 | 1.00 | 4 | 47 | 0 | 51 | 0 |
| grade | 32 | 0.98 | 1 | 3 | 0 | 11 | 0 |
| population | 0 | 1.00 | 1 | 2 | 0 | 4 | 0 |
| multiversions | 1888 | 0.02 | 1 | 1 | 0 | 1 | 0 |
| url | 0 | 1.00 | 33 | 275 | 0 | 462 | 0 |
| createddate | 0 | 1.00 | 8 | 10 | 0 | 203 | 0 |
| timestamp | 0 | 1.00 | 20 | 20 | 0 | 3 | 0 |
Variable type: logical
| skim_variable | n_missing | complete_rate | mean | count |
|---|---|---|---|---|
| tracking | 996 | 0.48 | 1 | TRU: 926 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| samplesize | 3 | 1 | 5.38e+03 | 6109.48 | 515.0 | 1.27e+03 | 1.50e+03 | 1.50e+04 | 2.20e+04 | <U+2587><U+2581><U+2581><U+2583><U+2581> |
| weight | 0 | 1 | 5.70e-01 | 0.59 | 0.0 | 1.20e-01 | 2.10e-01 | 8.90e-01 | 3.16e+00 | <U+2587><U+2583><U+2581><U+2581><U+2581> |
| influence | 0 | 1 | 2.00e-02 | 0.09 | 0.0 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.02e+00 | <U+2587><U+2581><U+2581><U+2581><U+2581> |
| approve | 0 | 1 | 5.14e+01 | 4.38 | 38.0 | 4.80e+01 | 5.20e+01 | 5.40e+01 | 6.30e+01 | <U+2581><U+2585><U+2587><U+2586><U+2581> |
| disapprove | 0 | 1 | 4.25e+01 | 5.94 | 28.0 | 3.80e+01 | 4.20e+01 | 4.70e+01 | 5.80e+01 | <U+2582><U+2587><U+2586><U+2585><U+2581> |
| adjusted_approve | 0 | 1 | 5.12e+01 | 3.70 | 40.4 | 4.94e+01 | 5.17e+01 | 5.36e+01 | 6.35e+01 | <U+2581><U+2583><U+2587><U+2583><U+2581> |
| adjusted_disapprove | 0 | 1 | 4.24e+01 | 4.43 | 27.3 | 3.92e+01 | 4.20e+01 | 4.52e+01 | 5.52e+01 | <U+2581><U+2583><U+2587><U+2583><U+2581> |
| poll_id | 0 | 1 | 7.52e+04 | 709.25 | 74246.0 | 7.46e+04 | 7.49e+04 | 7.56e+04 | 7.69e+04 | <U+2587><U+2586><U+2583><U+2582><U+2582> |
| question_id | 0 | 1 | 1.43e+05 | 2095.44 | 139394.0 | 1.40e+05 | 1.43e+05 | 1.44e+05 | 1.46e+05 | <U+2587><U+2581><U+2586><U+2585><U+2583> |
# Use `lubridate` to fix dates, as they are given as characters.
approval_polllist <- approval_polllist %>%
mutate(modeldate = mdy(modeldate)) %>%
mutate(startdate = mdy(startdate)) %>%
mutate(enddate = mdy(enddate)) %>%
mutate(createddate = mdy(createddate))
str(approval_polllist)## spec_tbl_df [1,922 x 22] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ president : chr [1:1922] "Joseph R. Biden Jr." "Joseph R. Biden Jr." "Joseph R. Biden Jr." "Joseph R. Biden Jr." ...
## $ subgroup : chr [1:1922] "All polls" "All polls" "All polls" "All polls" ...
## $ modeldate : Date[1:1922], format: "2021-10-18" "2021-10-18" ...
## $ startdate : Date[1:1922], format: "2021-01-19" "2021-01-19" ...
## $ enddate : Date[1:1922], format: "2021-01-21" "2021-01-21" ...
## $ pollster : chr [1:1922] "Morning Consult" "Rasmussen Reports/Pulse Opinion Research" "Ipsos" "YouGov" ...
## $ grade : chr [1:1922] "B" "B" "B-" "B+" ...
## $ samplesize : num [1:1922] 15000 1500 1115 1516 1993 ...
## $ population : chr [1:1922] "a" "lv" "a" "a" ...
## $ weight : num [1:1922] 0.259 0.338 1.101 1.245 0.093 ...
## $ influence : num [1:1922] 0 0 0 0 0 0 0 0 0 0 ...
## $ approve : num [1:1922] 50 48 55 45 56 51 58 52 48 63 ...
## $ disapprove : num [1:1922] 28 45 32 28 31 28 32 29 47 37 ...
## $ adjusted_approve : num [1:1922] 48.6 50.5 53.9 46.5 54.6 ...
## $ adjusted_disapprove: num [1:1922] 31.2 38.8 33 28.4 34.2 ...
## $ multiversions : chr [1:1922] NA NA NA NA ...
## $ tracking : logi [1:1922] TRUE TRUE NA NA NA TRUE ...
## $ url : chr [1:1922] "https://morningconsult.com/form/global-leader-approval/" "https://www.rasmussenreports.com/public_content/politics/biden_administration/biden_approval_index_history" "https://www.ipsos.com/sites/default/files/ct/news/documents/2021-01/2021_reuters_tracking_-_core_political_pres"| __truncated__ "https://docs.cdn.yougov.com/u3h9dresbn/20210120_yahoo_coronavirus_toplines.pdf" ...
## $ poll_id : num [1:1922] 74272 74247 74248 74327 74246 ...
## $ question_id : num [1:1922] 139491 139395 139404 139570 139394 ...
## $ createddate : Date[1:1922], format: "2021-01-28" "2021-01-22" ...
## $ timestamp : chr [1:1922] "09:38:10 18 Oct 2021" "09:38:10 18 Oct 2021" "09:38:10 18 Oct 2021" "09:38:10 18 Oct 2021" ...
## - attr(*, "spec")=
## .. cols(
## .. president = col_character(),
## .. subgroup = col_character(),
## .. modeldate = col_character(),
## .. startdate = col_character(),
## .. enddate = col_character(),
## .. pollster = col_character(),
## .. grade = col_character(),
## .. samplesize = col_double(),
## .. population = col_character(),
## .. weight = col_double(),
## .. influence = col_double(),
## .. approve = col_double(),
## .. disapprove = col_double(),
## .. adjusted_approve = col_double(),
## .. adjusted_disapprove = col_double(),
## .. multiversions = col_character(),
## .. tracking = col_logical(),
## .. url = col_character(),
## .. poll_id = col_double(),
## .. question_id = col_double(),
## .. createddate = col_character(),
## .. timestamp = col_character()
## .. )
## - attr(*, "problems")=<externalptr>Average net approval rate
Then we calculate the average net approval rate (approve- disapprove) for each week since he got into office (Jan 20th 2021), and get the mean, standard deviation, and 95% confidence interval of the weekly net approval.
approval_polllist_avg_approval <- approval_polllist %>%
mutate(net_approval = approve - disapprove) %>%
mutate(end_week = week(enddate)) %>%
group_by(end_week) %>%
summarise(average_net_approval = mean(net_approval), sd_net_approval = sd(net_approval),
count = n(), se_net_approval = sd_net_approval/sqrt(count), upper_bound = average_net_approval +
se_net_approval * qt(0.975, count - 1), lower_bound = average_net_approval -
se_net_approval * qt(0.975, count - 1))
approval_polllist_avg_approval## # A tibble: 40 x 7
## end_week average_net_approval sd_net_approval count se_net_approval upper_bound
## <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 3 18.6 8.23 11 2.48 24.2
## 2 4 18.5 8.94 51 1.25 21.0
## 3 5 16.7 7.59 54 1.03 18.8
## 4 6 16.6 8.16 37 1.34 19.3
## 5 7 16.3 7.34 50 1.04 18.4
## 6 8 15.0 7.77 50 1.10 17.2
## 7 9 13.4 7.46 53 1.02 15.4
## 8 10 12.9 7.08 49 1.01 15.0
## 9 11 15.8 7.45 43 1.14 18.1
## 10 12 14.7 9.32 57 1.23 17.2
## # ... with 30 more rows, and 1 more variable: lower_bound <dbl>Biden’s weekly average net approval rate plot is then generated, along with the smooth line and 95% confidence interval.
ggplot(approval_polllist_avg_approval, aes(x=end_week,y=average_net_approval)) +
geom_point(color="red")+
geom_line(color="red")+
geom_smooth(se=F,span=1)+
geom_ribbon(aes(ymin=lower_bound,ymax=upper_bound),alpha=0.1,color="grey")+
scale_y_continuous(limits=c(-10,25))+
geom_hline(yintercept=0,color="orange",size=1.5)+
theme_minimal() +
theme(plot.title =element_text(size=16, face='bold',hjust = 0.5,margin = margin(10,0,10,0)),
plot.subtitle =element_text(size=16, face='bold',hjust = 0.5), #put titles in the middle
axis.text.x = element_text(size=10),
axis.text.y = element_text(size=12),
axis.ticks.x = element_line(),
axis.ticks.y=element_line(),
axis.title.x = element_text(size=16,face='bold'),
axis.title.y = element_text(size=16,face='bold'),
) +
labs(title = "Biden Net Approval Rate",
subtitle = "Weekly Average",
x = "Week",
y = "",
caption = "Source: https://projects.fivethirtyeight.com/biden-approval-ratings") +
ylab("Average net approval rate")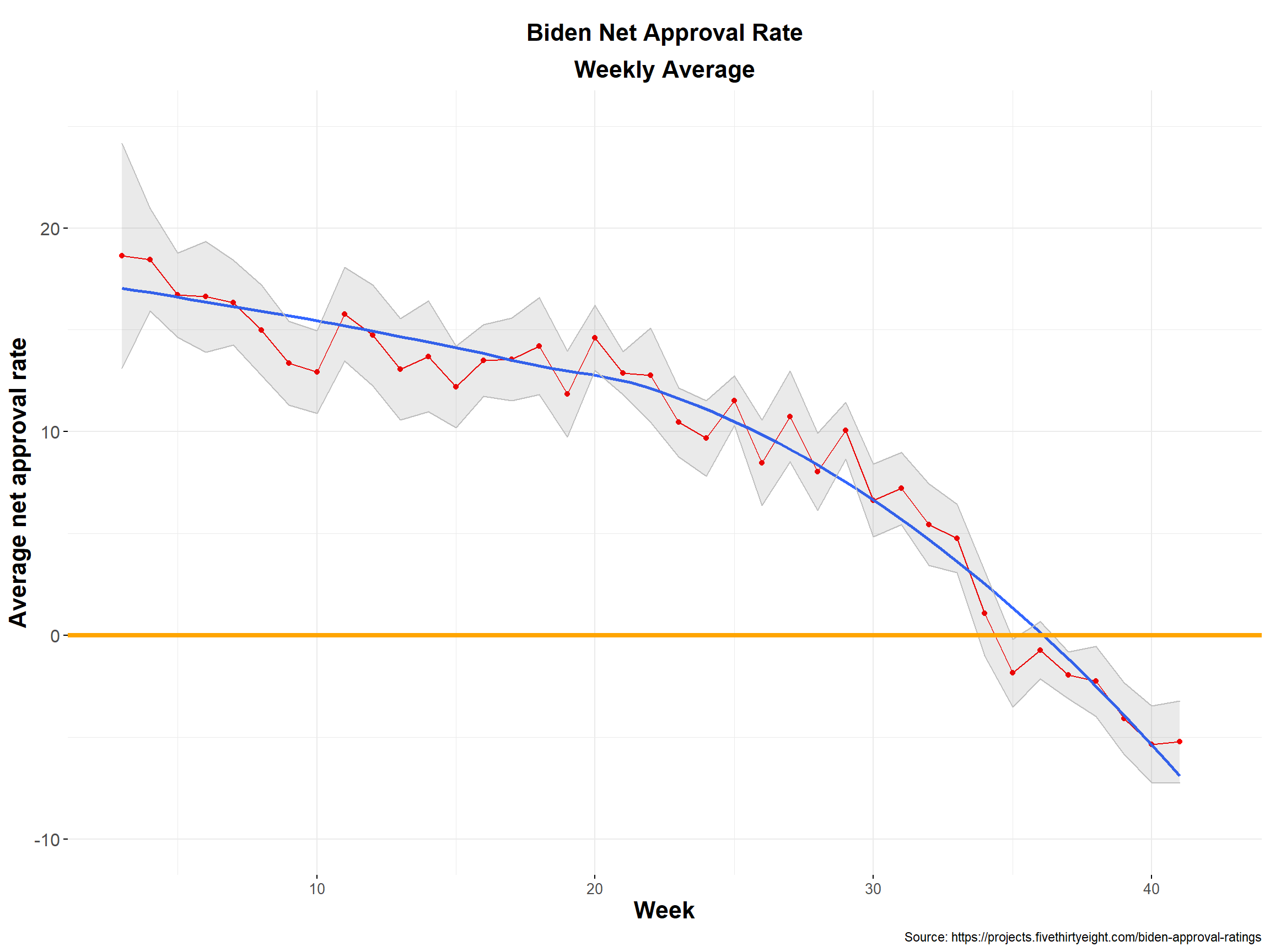
Confidence Intervals for Week 3 and Week 25
The confidence intervals for week 3 and week 25 are respectively the largest and the smallest. In week 3 the confidence interval ranges between 13 and 24, whereas in week 25 the lower bound is 10 and the upper bound 13. The difference is due to the sample size of the data. The much higher number of values for week 25 decreases exponentially the standard error, that is in fact 0.6 compared to the 2.5 for week 3.
Wrong content? Edit on Github.
💬 Comment: